

It demonstrated that a new data protection at least backup approach is needed. Founded in June 2014 by Tarun Thakur and Prasenjit Sarkar, with strong background in data management with experiences at Data Domain, IBM, SolidFire and Nimble Storage, Datos IO has raised $15.25M in 2 rounds from Lightspeed Ventures Partners and True Ventures.
The company has already 10 customers after 6 months of GA, growing fast, 40+ in the pipeline indicating that the solution has its place in the new data protection landscape shaking historical established positions with Cohesity and Rubrik for global secondary storage. Great.
So what is the problem ? and Why Datos IO is well positioned to become rapidly the de-facto leader in this category ?
- Distributed and Scale-out data model is now a reality increasing complexity for protection to sustain RPOs and RTOs,
- Databases have changed a lot with new offering around non-relational model aka NoSQL with various flavors: Key-Value, Document, Column or Graph… such Cassandra, MongoDB, Redis or Neo4j,
- Data volume are growing fast and volume is really big, Hadoop/HDFS/HBase… have arrived,
- Analytics is very common,
- Applications and DBs are moving to the cloud and finally users have adopted the subscription mode. Even some of them span private and public cloud fully transparently for users.
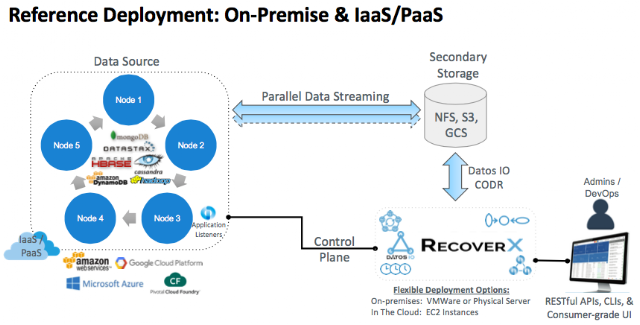
Datos IO has targeted in the 1st phase cloud and non-relational databases and plan to address mobility for more classic solutions such MySQL or PostgreSQL and finally will integrate analytics and search with Elasticsearch. Datos IO RecoverX, today in 1.5, relies on CODR – Consistent Orchestrated Distributed Recovery – a cloud elastic compute engine that could be deployed on EC2 or on-prem on vSphere or physical server, able to stream data in parallel and with semantic global deduplication.
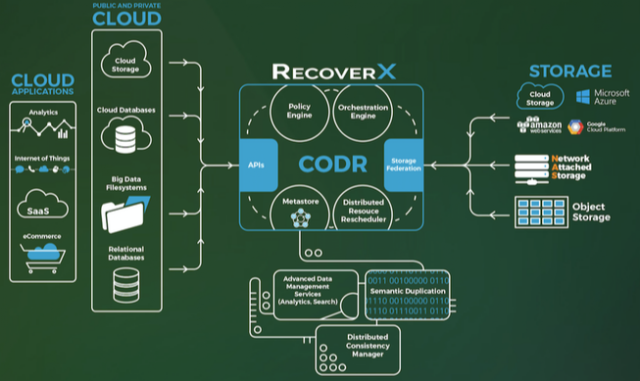
As databases are distributed, the company implements a listener technique installed on every node to stream data in parallel from/to secondary storage that can be NFS, S3 or Google Cloud Storage for instance. RecoverX as a data management product is responsible to control, manage and orchestrate data protection but not to store data by itself. Among several key features, the product offers scalable versioning, semantic deduplication and cluster consistent backup. In term of pricing, RecoverX is offered with an annual subscription with support included plus a capacity fee based on physical database size. For market adoption, Datos IO seems to be a perfect product for oem and channel with direct enterprise touch to preach the new approach. We expect great things with RecoverX 2.0 in 2017 with Big Data File Systems, Azure and more relational DBs… all good topics for our next visit to Datos IO.















0 commentaires:
Post a Comment